
bdfgdfg
[C++ 11] std::atomic, SpinLock 본문
std::atmoic
atomic은 원자라는 의미를 가지며 원자적 연산(더 이상 쪼개질 수 없는 연산)을 진행한다.
원자적 연산은 처리하는 중간에 다른 스레드가 끼어들 여지를 주지 않으며 전부 처리하거나 or 아무것도 하지 못했다. 이 두 가지 상황만이 존재하는 연산. 즉 한번에 일어나는 연산. d
이것은 싱글 쓰레드 환경에서는 중요치 않지만, 멀티 쓰레드 환경에서는 중요한 개념.
-> 둘 이상의 스레드가 공유 자원에 접근할 때 발생할 수 있는 문제를 경쟁 상태(Race condition)이라 한다.
-> 경쟁 상태는 mutex와 같은 상호 배제 객체로도 해결이 가능하지만, atomic연산을 통해서도 위의 문제를 방지할 수 있다.
-> 경쟁 상태가 문제가 되는 이유는 운영체제의 콘텍스트 스위칭(Context Swiching, 문맥 교환)때문.
-> C++11이전에는 Interlocked(인터락) 함수를 사용하였음.
-> std::mutex와 같이 c++11에 추가된 상호 배제 객체는 유저 모드 동기화. 내부적으로 원자적 연산(CAS)을 통해 락을 얻고 반환.
또한 atomic연산은 메모리 가시성 문제또한 해결한다. 가시성이란 멀티 코어의 캐시(Cache) 간 불일치의 문제를 말하는데, 하나의 스레드에서 특정한 변수의 값을 수정하였는데, 다른 스레드에서 그 수정된 값을 제대로 읽어 들인다는 보장이 없다. (참고로 C++의 volatile은 JAVA와는 달리 가시성 문제를 해결해주지 않는다. 단순히 컴파일러 최적화를 막기만 함)
CPU에서 메모리에 선언된 변수를 읽어 들일 때 최적화를 위해 해당 메모리와 주위의 메모리를 가져가 캐시에 저장한다.


위 그림과 같이 메인 메모리에서 Thread1에서 메인 메모리에 있는 counter를 읽어와 7이라는 값으로 수정하였지만
Thread 2에서는 그 사실을 인지하지 못하고, 0이라는 값을 들고 있는 counter를 메인 메모리에서 가져와 작업을 진행한다.
문제는 정확히 언제 캐시에서 메인 메모리로 다시 저장할지를 알 수 없기에 멀티 스레드 환경에서 쓰레드가 공유 변수에 동시에 접근이 가능한 상황(이런 상황을 임계영역이라 한다)이라면 원자적 연산은 필수다.
이제 멀티 쓰레드 환경에서 왜 원자적 연산의 키워드가 중요한지 두 개의 코드를 보면서 살펴본다.
먼저 경쟁상태(Race Condition)의 문제
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
// ConsoleApplication6.cpp : 이 파일에는 'main' 함수가 포함됩니다. 거기서 프로그램 실행이 시작되고 종료됩니다.
//
#include <iostream>
#include <thread> // C++11에서 나온 쓰레드 헤더
int g_sum = 0;
void Add()
{
for (int inc = 0; inc < 1000000; ++inc)
g_sum++;
}
void Sub()
{
for (int inc = 0; inc < 1000000; ++inc)
g_sum--;
}
int main()
{
std::thread t1(Add);
std::thread t2(Sub);
t1.join();
t2.join();
std::cout << g_sum;
return 0;
}
|
cs |
전역 변수인 g_sum을 Add함수에서는 100만 번만큼 +1 증가시키고, Sub함수에서는 -1 감소한다.
예상한 결과는 0이 되어야 하지만 실행해보면
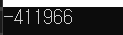


0이라는 값은커녕, 매번 실행할 때마다 다른 값이 튀어나온다.
이 문제는 두 스레드가 동시에 공유 변수에 write 하는 상황에서 콘텍스트 스위칭이 일어나면서 발생하는 문제.


위 사진에서 연산이 진행되는 순서는 다음과 같다.
1. 메인 메모리의 변수에 있는 값을 CPU의 레지스터에 저장한다.
2. 레지스터에 있는 값을 증감 연산한다.
3. 레지스터에 있는 값을 메인 메모리의 변수가 저장된 곳에 write 한다.
이렇게 총 3가지의 단계를 거친다.
만약 g_sum이 0이었고 g_sum++명령을 읽는 순간 CPU 레지스터로 읽어오고 +1 연산을 한 뒤 메인 메모리에 저장할려는데 콘텍스트 스위칭이 일어나면서 g_sum--의 명령이 수행되었다고 보자.
그럼 현재 메모리에 저장된 g_sum의 값은-1. 여기서 다시 g_sum++연산을 진행하던 스레드로 콘텍스트 스위칭이 되면서 이전에 처리하던 작업을 이어서 처리하기 위해 메인 메모리에 +1 연산한 값 1을 메모리에 저장한다.
우리가 원하는 결과는 +1 - 1 = 0 이 되어야 하지만, 위와 같은 문제로 제대로 연산이 진행되지 않은 것.
이 문제를 해결하기 위해서 atomic연산이 필요하다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
#include <iostream>
#include <thread> // C++11에서 나온 쓰레드 헤더
#include <atomic>
std::atomic<int> g_sum = 0; // atomic객체 사용.
void Add()
{
for (int inc = 0; inc < 1000000; ++inc)
g_sum++;
}
void Sub()
{
for (int inc = 0; inc < 1000000; ++inc)
g_sum--;
}
int main()
{
std::thread t1(Add);
std::thread t2(Sub);
t1.join();
t2.join();
std::cout << g_sum;
return 0;
}
|
cs |
실행해보면

원하는 0이라는 값이 제대로 출력된다. (몇 번을 실행해도 같다.)
이렇게 atomic연산을 이용하여 연산 도중 다른 스레드가 끼어들 여지를 없앨 수 있다.
참고로 ++,--는 내부적으로 연산자 오버 로딩으로 처리되어 가능한 것이며
|
1
2
3
4
5
6
7
8
9
10
|
void Add()
{
for (int inc = 0; inc < 1000000; ++inc)
g_sum.fetch_add(1);
}
void Sub()
{
for (int inc = 0; inc < 1000000; ++inc)
g_sum.fetch_sub(1);
}
|
cs |
위와 같이 fetch_add, fetch_sub함수를 사용해도 동일한 처리를 한다.
좀 더 가독성을 위해서 원자적 연산이라는 것을 전달하기 위해 멤버함수를 통해 사용하는것이 좋다.
그다음 메모리 가시성 문제 + 코드 재배치 문제
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
int x = 0;
int y = 0;
int r1 = 0;
int r2 = 0;
volatile bool ready;
void Thread_1()
{
while (!ready);
y = 1; // 쓰기
r1 = x; // 읽기
}
void Thread_2()
{
while (!ready);
x = 1; // 쓰기
r2 = y; // 읽기
}
int main()
{
int count = 0;
while (true)
{
ready = false;
++count;
x = y = r1 = r2 = 0;
std::thread t1(Thread_1);
std::thread t2(Thread_2);
ready = true;
t1.join();
t2.join();
if (r1 == 0 && r2 == 0)
break;
}
//
std::cout << count << " 번만에 빠져나옴 ~" << std::endl;
}
|
cs |
위 코드에서 메인 함수에서 무한 루프를 돌면서 2개의 쓰레드를 생성하여 Thread1,Thread2함수를 호출하는데, 만약 r1값과 r2의 값이 메인 쓰레드에서 관찰했을 때 둘 다 0이라면 빠져나오는 코드이다.
위의 코드를 실행해보면 몇천번만에 빠져나올수도 있고 계속해서 무한루프에 빠질수도 있다.
여기서 중요한것은 빠져나오는 상황이 발생할 수도 있다는 점.
위 코드를 봤을 때 r1과 r2는 항상 먼저 x,y가 먼저 1이라는 값을 write한 후에 read하고 있다. 그렇다면 어떻게 위에서
메인함수의 루프문을 빠져나올 수 있을까. 그것은 바로 메모리 가시성 문제와 코드 재배치 문제.
우선 가시성 문제부터 생각해보자.
가시성은 쓰레드에서 어떤 변수의 값을 읽어와 write를 하는데, 그게 100% 메모리에다가 바로 write한다는 보장은 없다.
여기서 다른 쓰레드가 위의 변수를 읽어올 때 수정된 값이 아닌 기존의 값을 읽어올 수 있다는 것.
즉 Thread_1,Thread_2 두 함수를 실행하는 쓰레드에서 각각 x,y에 1이라는 값을 write하고, r1,r2에 write한다 하더라도
메인 쓰레드가 관찰할때는 수정된 값이 아닌 기존의 값인 0,0을 읽어들여 빠져 나오는 것.
또한 코드 재배치의 문제로 인해 빠져 나올수도 있다.
컴파일러는 딱히 멀티쓰레드 환경을 고려하지 않기에 코드를 보고 순서를 뒤바꿀 수도 있다.
-> 싱글 쓰레드 환경이라면 어차피 결과는 같기에 상관없지만, 멀티 쓰레드 환경이라면 이야기가 다르다.
만약 컴파일러가 코드 재배치를 하지 않았더라도, CPU가 명령어를 실행할때에도 명령어를 재배치할 수 있다.
-> 이게 가능한 이유는 현대의 CPU가 한번에 명령어를 실행하는게 아니기 때문.
-> CPU는 명령어를 실행할 때 Fetch(읽기),Decode(해석),Execute(실행),Write(쓰기)와 같은 단계를 거친다.

즉 CPU가 명령어를 읽어들일 때에 하나의 명령어의 Fetch가 끝났다면 이어서 다른 명령어의 Fetch를 진행한다는 이야기.
(이렇게 동시에 여러개의 작업을 동시에 처리하는 것을 CPU 파이프라이닝이라 한다)
위 그림에서는 명령어의 단계별 실행속도가 동일한것처럼 나타났지만, 실제로는 실행 부분의 속도는 명령어마다 다르다.
만약 실행시간이 오래 걸리는 명령어가 있다면 해당 작업 때문에 다른 명령어 들이 밀리게 된다.
그렇기에 컴파일러는 최대한 CPU의 파이프라인을 효율적으로 활용할 수 있도록 코드를 재배치하게 된다.
-> 여기서 문제는 컴파일러가 코드를 재배치할 떄 다른 쓰레들을 고려하지 않는다는 것.
또한 CPU도 명령어를 재배치한다고 했다.
|
1
2
3
|
// 현재 a = 0, b = 0;
a = 1; // 캐시에 없음
b = 1; // 캐시에 있음
|
cs |
a = 1의 경우 현재 a가 캐시에 존재하지 않으므로 Cache Miss가 일어나며 메모리까지 가서 a를 읽어온다.
반면에 b = 1의 경우에는 현재 b가 캐시에 존재하므로 Cache hit가 일어나 빠르게 처리가 가능하다.
따라서 CPU가 판단하기에 위 코드가 실행될 때, a = 1보다 b = 1이 먼저 실행될 수 있다는 것.
-> 즉 다른 쓰레드에서 a는 0인데 b는 1인 경우를 관찰할 수 있다.
다시 코드로 돌아와서,
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
void Thread_1()
{
while (!ready);
r1 = x; // 읽기
y = 1; // 쓰기
}
void Thread_2()
{
while (!ready);
r2 = y; // 읽기
x = 1; // 쓰기
}
|
cs |
위의 경우처럼 원래의 순서인 쓰기-읽기순서가 아닌 컴파일러나 CPU가 판단에 의해 코드 재배치가 이루어질 수 있다.
메모리 모델
C++에서 모든 쓰레드들이 수정 순서에 동의하는 경우는 원자적 연산을 진행할 때이다.
여기서 말하는 수정순서는 밑의 그림과 같다.

코드 재배치의 문제에서 명령어의 순서가 뒤죽 박죽 섞여 우리가 생각했던 순서대로 실행되지 않을 수 있다.
하지만 원자적 연산을 이용하면 위의 그림과 같이 동일 객체에 대해서 동일한 수정 순서를 관찰할 수 있다.
-> a의 값을 5로 읽었다면 그 다음 관찰 가능한 값은 8,6,3이어야 한다. 과거의 값을 읽는일은 없다.
-> 즉 가시성의 해결.
기본적으로 atomic클래스의 모든 연산은 기존의 가시성 문제와 코드재배치의 문제를 바로 해결해준다.
다만 그 이유는 메모리 모델의 정책을 Sequential Consistency정책이 Default로 설정되어 있기 때문.
atomic 연산의 메모리 모델 정책은 크게 세가지가 존재한다.
1. seq_cst(가장 엄격하며 가시성,코드 재배치등의 문제를 해결) - 이때까지 쓰던 것
2. acquire-release (1번과 3번사이의 중간)
3. relaxed (원자성만 보장. 가시성,코드재배치등이 발생할 수 있음. 거의 사용x)
2번의 설명만이 애매하니 2번만 자세히본다.
2번의 acquire-release는 release명령 이전의 명령어들이 release명령 이후로 재배치 되는 것을 금지한다.
또한 acquire을 호출하는 쓰레드가 있다면 release이전의 명령들이 acquire하는 순간에 관찰이 가능하다.
(가시성 보장)
즉
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
std::atomic<bool> flag;
int test = 0;
void Producer()
{
test = 100;
//
// release위의 모든 명령들은 acquire이후에 보인다.
// 또한 위의 명령들은 release밑으로 재배치 되는것을 막는다.
flag.store(true,std::memory_order_release);
}
void Consumer()
{
while(flag.load(std::memory_order_acquire) == false);
// 이후부터 Release 이전에 쓰여진 메모리 값들이 보인다.
// 또한 acquire 이후의 명령어들이 acquire위로 재배치 되는것을 막는다.
std::cout << test << std::endl;
}
int main()
{
flag.store(false); // flag = true와 동일.
std::thread t1(Producer);
std::thread t2(Consumer);
t1.join();
t2.join();
}
|
cs |
인텔이나 AMD의 CPU경우 순차적 일관성을 보장하기에 SEQ_CST를 써도 별다른 부하가 없다고 한다.
-> ARM의 경우에는 다르다고 함.
CAS 함수(Compare And Swap)
간단하게 유저모드 동기화 기법인 SpinLock 클래스를 구현해보자.
SpinLock은 락을 얻으려고 할 때 해당 락이 이미 다른 누군가가 얻은 상태라면 루프를 돌면서 락을 획득가능한지 계속해서 확인하는 busy-waiting상태에 빠지는것을 말한다.
-> 락을 금방 획득한다면 컨텍스트 스위칭이 일어날 필요없이 바로 이어서 작업이 가능.
-> 반대로 락을 얻는데 오래걸린다면 오랫동안 busy-waiting상태에 빠지므로 overhead가 발생.
-> 유저모드 동기화
먼저 간단하게 생각해보면 하나의 bool변수를 하나두고 해당 bool변수가 true라면 락을 얻었다는 상황이라 보고, 다른 쓰레드가 접근할 때 무한루프를 돌게끔한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
class MySpinLock
{
public:
void Lock()
{
while (m_locked); // 다른 누군가 lock을 획득했다면 무한루프.
m_locked = true;
}
void UnLock()
{
m_locked = false;
}
private:
bool m_locked = false;
};
|
cs |
위와 같이 구현하고 처음에 경쟁상태 문제의 Add,Sub함수에서 lock을 써보면
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
int g_sum = 0;
MySpinLock lock;
void Add()
{
for (int inc = 0; inc < 1000000; ++inc)
{
lock.Lock();
g_sum++;
lock.UnLock();
}
}
void Sub()
{
for (int dec = 0; dec < 1000000; ++dec)
{
lock.Lock();
g_sum--;
lock.UnLock();
}
}
int main()
{
std::thread t1(Add);
std::thread t2(Sub);
t1.join();
t2.join();
std::cout << g_sum << std::endl;
return 0;
}
|
cs |
실행해보면

예상한 값인 0이아닌 다른 값이 출력된다.
이러한 문제가 발생하는 이유는 두 쓰레드가 동시에 락을 얻는경우가 발생하기 때문.
화장실에 비유해보면 화장실에 들어가고 문을 잠구는 행위가 한번에 일어나지 않기때문.
즉 화장실이 비었는지 확인하고(while(m_locked)) 들어갔다면 (m_locked = true)가 한번에 일어나지 않기때문에 발생하는 문제라는 것.
여기서 원자적연산이 필요하다.
한번에 화장실에 들어간다음 문을 잠구거나 혹은 실패하거나 둘 중 하나의 상황만이 존재해야한다.
이 때 사용할 수 있는게 CAS(Compare And Swap)함수.

바로 compare_exchange~계열의 함수. 비교와 교환을 원자적으로 처리한다.
-> C++11이전에는 InterlockedExchange를 사용.
먼저 함수원형을 보면 bool값을 반환하며, 첫번째 인자로는 bool&를 받고 두번쨰 인자로는 bool값을 받는다.
첫번째 인자인 expected는 m_locked가 어떤값인지 기대(Expected)한다. 만약 기대하는 값과 동일하다면 desired로 넘긴값으로 변경한다. 그리고 true를 반환.-> 이 작업이 원자적으로 처리.
간단한 예시를 보면
|
1
2
3
4
5
6
|
std::atomic<int> intAto;
intAto.store(10);
int expected = 5;
int desired = 20;
bool retValue = intAto.compare_exchange_strong(expected, desired);
|
cs |
현재 int형 atomic객체가 저장하고 있는 값은 10. CAS함수의 인자로 넘긴 expected값은 5이고 desired값은 20이다.
현재 atomic객체가 들고 있는 값(10)과 expected의 값(5)은 서로다르므로 desired로 바꾸지 않고 false를 반환한다.


atomic객체의 값도 그대로다. 단 하나 변경되는 값이 있다. 위에서 expected의 인자는 &(참조자)로 인자를 받는것을
알 수 있는데, 만약 atomic객체가 expected의 값을 갖고있지않아 false를 반환할 때.
expected의 값을 현재 atomic객체가 들고 있는 값(10)으로 설정하고 false를 반환한다.

이제 expected의 값을 10으로 변경하고 실행해보면
|
1
2
3
4
5
6
|
std::atomic<int> intAto;
intAto.store(10);
int expected = 10;
int desired = 20;
bool retValue = intAto.compare_exchange_strong(expected, desired);
|
cs |

desired의 값으로 변경된것을 알 수 있다.
이렇게 값을 비교하고 값을 교환하는 것을 원자적으로 처리하는것을 SpinLock클래스에서도 그대로 적용해보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
class MySpinLock
{
public:
void Lock()
{
bool expected = false;
bool desired = true;
// 다른 누군가 lock을 획득했다면 무한루프.
while (m_locked.compare_exchange_strong(expected, desired) == false)
{
expected = false;
}
}
void UnLock()
{
m_locked.store(false);
}
private:
std::atomic<bool> m_locked = false;
};
|
cs |
이제 Add와 Sub를 호출하는 두 쓰레드를 실행해보면

제대로 0이 출력되는걸 알 수 있다.
정리하면 atomic연산은 한번에 모두 처리하거나 or 실패하거나 둘 중 하나의 상황만이 존재하는 연산.
atomic연산을 통해 동일 객체의 동일 수정 순서를 관찰가능하며, 경쟁상태,가시성,코드 재배치의 문제를 해결할 수 있다.
당연하지만 atomic연산은 무겁다. 멀티 쓰레드 환경이라 하더라도 모든 연산을 atomic처리해야한다는게 아니라, 위의 문제가 발생할 수 있는 상황일 때 atomic연산을 고려해 사용해야 한다.
참고한 사이트 - https://modoocode.com/271
'게임프로그래밍 > C++' 카테고리의 다른 글
| [C++ 11] std::function, std::bind (0) | 2022.02.15 |
|---|---|
| [C++ 11] 스마트 포인터(Smart Pointer) - 2 (0) | 2022.01.26 |
| [C++ 11] 스마트 포인터(Smart Pointer) - 1 (0) | 2022.01.26 |
| [C++ 11] 오른값 참조 및 이동 의미(move semantic) (0) | 2022.01.25 |
| [C++ 11] 람다(lambda) 식 (0) | 2022.01.24 |



