
bdfgdfg
[OS] 가상 메모리 본문
메모리 할당방식
메모리보다 더 큰 프로그램을 메모리에 어떻게 올릴까?
방법은 간단하다. 롤이라는 프로그램을 당장 실행되는 부분만 메모리에 올리고 나머지 부분은 하드디스크에 저장한다.
-> 정확히는 하디스크 내 스왑영역이라는 곳에 저장된다.
-> 이 기법을 메모리 오버레이이라고 한다.
이 기법을 통해 사용자는 메모리가 적은 컴퓨터를 사용하더라도 크기가 큰 프로그램을 실행시킬 수 있다.
하지만 스왑이라는 과정을 거치기에 메인 메모리가 큰 컴퓨터보다는 느리게 동작한다.
-> 스왑 : 스왑영역에 있는 데이터 일부를 메모리로 가져오고(스왑인) 메모리에 있는 데이터를 스왑영역으로 옮기는 것(스왑아웃).
이 과정은 옛날의 일괄처리 방식(한번에 하나의 프로세스만을 처리)에서도 사용된 기법.
그렇다면 멀티프로세스 환경에서는 이 과정을 어떻게 거칠까. 시분할 방식에서는 여러 프로세스가 동시에 실행되게끔 보이도록 처리하기 위해 메모리에 여러 프로세스가 올라온다.
그렇기에 메모리를 나누는 방법이 존재하고 그 방법은 2가지가 존재한다.
1. 가변 분할 방식(세그멘테이션)
-> 프로세스의 크기에 따라 메모리를 나누는 방식. (프로세스가 크면 메모리도 크게 할당)
2. 고정 분할 방식(페이징)
-> 프로세스 크기와 상관없이 메모리를 할당.
가변 분할 방식의 장점은 메모리에 연속된 공간에 할당되기에 더 크게 할당되어 낭비되는 공간인 내부 단편화가 없다.
단점으로는 외부 단편화가 존재한다. -
> 메모리에 서로 다른 크기의 여러개의 프로세스가 올라왔다고 생각해보고 프로세스 두개가 종료되면 그 두 개의 프로세스 공간이 남게된다.
(만약 하나의 프로세스는 50MB이고 다른 프로세스가 10MB라고 하면 각각 50MB,10MB가 남는 것)
여기서 크기가 60MB인 프로세스가 메모리에 올라가길 원하고, 현재 위의 상태에서 딱 60MB가 빠지니 가능할것같지만, 두 프로세스가 빠진 상태에서 메모리는 연속적으로 공간이 빠진것이 아니기에 새로운 프로세스에게 메모리를 할당할 수 없다.
이것을 외부 단편화라고 한다.
-> 해결법으로는 외부 단편화가 발생한 공간을 합쳐주는 조각 모음을 하면 된다. 하지만 조각 모음을 하려면 현재 메모리에서 실행되고 있는 프로세스들을 일시 중지하고 메모리 공간을 이동시키는 작업을 해야하기에 오버헤드가 발생한다.
고정 분할 방식의 장점은 구현이 간단하고 오버헤드가 적다. (같은 크기로 나누기에 단순함)
단점은 크기가 작은 프로세스가 고정 분할 방식에서 정해진 크기보다 작다면 낭비되는 공간이 발생해 내부 단편화가 발생한다.
-> 20MB의 크기로 메모리를 고정되게 분할한다고 생각해보자.각각의 프로세스들이 20MB로 쪼개져 메모리에 올라온다. 프로세스 A와 B의 크기는 각각 15MB,10MB라고 할 때 이 둘은 고정 분할의 크기보다 작으므로 메모리에 한번에 올라오지만, 나머지 낭비 공간이 각각 5MB,10MB가 생기게 된다.이를 내부 단편화라 한다.이를 해결하는 방법은 분할되는 크기를 조절해서 내부단편화를 최소화 한다.
헷갈릴수도 있는점은 프로그램의 크기가 작다면 한번에 올라올 수 있지만 크기가 큰 프로그램의 경우 대부분 쪼개져서 메모리에 올라온다는 점을 잊지말아야 한다.
오늘날의 운영체제는 가변 분할 방식과 고정 분할 방식을 합쳐 단점을 줄였다.
가상메모리
컴퓨터마다 실제 메모리 크기가 다르다.
만약 운영체제나 프로세스가 4GB 메모리에서 동작하도록 만들어졌다면 이보다 작은 메모리를 가진 컴퓨터에서는 실행되지 않을 것이다.
가상 메모리는 이런 문제를 완벽히 해결했다.
-> 부족한 물리 메모리를 극복하기 위한 기술. 즉 실제 메모리보다 더 많아 보이는 기술.
-> 모든 프로세스를 메모리에 올리기에는 부족하기에 프로세스에서 사용하는 부분만 메모리에 올리고 나머지는 디스크에 저장하는 기법을 가상 메모리.
프로세스는 메모리 관리자를 통해세 메모리에 접근한다. 프로세스가 직접 물리 메모리에 접근할 일이 없고, 메모리 관리자에게 요청만 하면 된다.
가상메모리의 크기는 이론적으로는 무한대이지만 실제로는 물리 메모리의 크기와 CPU비트 수로 결정된다.
32BitCPU의 경우에는 표현할 수 있는 주소크기가 2^32. 총 4GB의 가상 메모리크기를 가진다.
만약 4GB크기를 가지는 프로세스가 5개가 있다고 해보자. 적어도 20GB라는 메모리 크기가 필요한데. 이럴 떄 가상메모리 시스템은 물리메모리 내용의 일부를 하드디스크에 있는 스왑 영역으로 옮기고, 처리가 필요할 때 물리 메모리로 가져와 실행시키기 때문에 운영체제와 프로세스 5개를 전부 실행시킬 수 있다.
메모리 관리자는 물리메모리와 스왑영역을 합쳐서 프로세스가 사용하는 가상주소를 물리주소로 변환하는데 이를 동적주소 변환이라 한다.
실제 물리 메모리의 0번지는 운영체제 영역이므로 프로세스가 사용할 수 없다.
가상 메모리 시스템에서는 운영체제 영역을 제외한 나머지 영역을 일정한 크기로 나누어서 프로세스에게 할당한다.
-> 가변 분할 방식과(세그멘테이션) 고정 분할 방식(페이징)으로 나뉜다.
-> 세그멘테이션은 외부 단편화문제. 페이징은 내부 단편화문제와 같은 단점이 존재한다.
-> 우리가 잘 아는 그 메모리 단편화가 외부 단편화.
-> 이 단점을 보완하기 위해 세그멘테이션-페이징 혼용기법을 사용한다.
가상메모리 시스템에서 가상주소는 메모리나 스왑영역 한 곳중에 위치한다.
메모리 관리자는 가상주소와 물리주소를 일대일 매핑 테이블로 관리한다.
세그먼트는 프로세스와 관련된 데이터들이 나누어지는 단위.
세그먼트 0번은 롤의 메모리일 수 있고, 세그먼트1번은 크롬의 메모리일수도 있다.
-> 즉 전체 메모리가 한번에 메모리에 올라오는게 아닌 세그먼트 단위로 나뉘어 올라온다.
-> 페이지와 비슷하지만 페이지는 고정 크기의 블록, 세그먼트는 가변 크기의 블록이다.
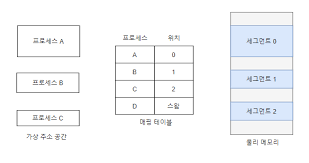
세그멘테이션(배치정책)
가변분할 방식을 이용하는 세그멘테이션 기법을 알아보자.
세그멘테이션에서 프로그램은 함수나 모듈등으로 세그먼트를 구성한다.
사용자와 프로세스 CPU가 바라보는 주소는 논리주소.
-> 실제 프로그래밍을 할 때 보는 주소값은 논리주소.
-> 이 논리적 주소는 메모리 관리자(MMU)를 통해 물리주소로 변환.
그럼 메모리 관리자는 어떻게 논리 주소를 물리주소로 변환 시켜줄까?
메모리 관리자는 세그멘테이션 테이블이라는 것을 가지고 있다.
세그멘테이션 테이블은 세그먼트번호,BaseAddress,Bound Address(세그먼트의 크기)정보를 나누어 저장하고 있다.
CPU에서 논리주소를 전달하면 메모리 관리자는 이 논리주소가 몇번 세그먼트인지 알 수 있다.
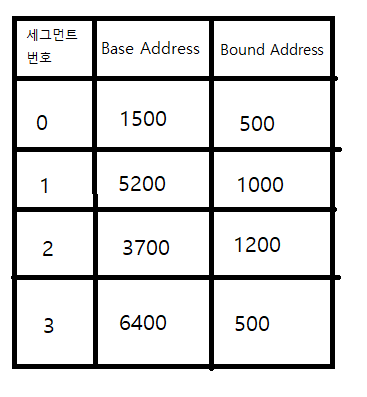
예로들어 논리주소 0x123번지의 물리 메모리주소를 요청할 떄 메모리 관리자는 이 논리주소가 몇번 세그먼트인지 알아낸다.
-> 메모리 관리자내에 Segment Table Base Register를 통해 물리 메모리내에 있는 세그멘테이션 테이블을 찾는다.
-> 참고로 컨텍스트 스위칭이 일어날 때 다른 프로세스로의 컨텍스트 스위칭이 일어나면, 메모리 관리자내에 Segment Table Base Register를 해당 프로세스의 것으로 값을 바꿔줘야 한다. (컨텍스트 스위칭의 작업이 무거운 이유)
세그먼트 번호를 인덱스로 BaseAddress와 BoundAddress를 참조한다.
Bound Address는 세그먼트의 크기를 나타낸다. 메모리 관리자는 cpu에서 받은 논리주소(0x123)와 Bound Address와의 크기를 비교한다. 만약 Bound Address의 크기보다 작다면 논리주소(123)와 Base Address(6400이라 가정)를 더해 물리 주소를 구하고(6523), 만약 논리주소의 크기가 Bound Address보다 크다면 메모리를 침범했다고 생각하고 에러를 발생시킨다.
CPU에서 세그먼트 1번이 0x632번지 논리주소를 물리주소로 변환을 한다고 해보자.
메모리 관리자는 cpu의 요청을 받고 세그먼트 1번인것을 알아내고 메모리 관리자내에 있는 STBR(Segment Table Base Register)를 이용해 세그멘트 테이블을 찾아낸다.
세그멘테이션 테이블을 찾은 후 1번 인덱스를 참고해 Bound Address와 크기를 비교하고 작다면 그대로 Base Address와 논리주소를 더해 물리주소를 구한다. (위 그림 참조)
세그멘테이션의 장점은 메모리를 가변적으로 분할할 수 있고 코드, 데이터, 스택,힙을 모듈로 처리할 수 있기때문에 공유와 각 영역에 대한 메모리 보호가 편하다.
단점으로는 가변 분할 방식의 단점인 외부 단편화가 발생한다.
페이징
세그멘테이션은 외부단편화가 존재하기에 이를 해결하기위해 나왔다.
-> 이를 해결하기 위한 조각모음은 오버헤드가 너무크다.
페이징은 메모리를 할당할 때 정해진 크기의 페이지로 나눈다.
-> 나누는 단위를 페이지라 한다.
모든 페이지는 크기가 같기에 관리가 쉽다. 또한 일정한 크기로 나누었기에 외부 단편화가 발생하지 않는다.
논리주소공간은 사용자와 프로세스가 바라보는 공간이고, 물리주소공간은 실제 메모리에서 사용되는 공간.
페이징에서 논리주소공간은 일정한 크기로 균일하게 나뉘고 이를 페이지라 한다.
물리주소 공간도 페이지의 크기와 동일하게 나뉘는데 이를 프레임이라 한다.
그럼 페이징은 어떻게 주소변환을 할까?
페이징도 메모리가 관리자가 테이블을 가지고 있는데 이를 페이지 테이블이라 한다.
즉 cpu가 논리주소 0x0번지의 물리주소를 요청하면 메모리 관리자는 해당 논리주소가 있는 페이지와 오프셋을 알아낸다.
그리고 메모리 관리자내에 Page Table Base Register(PTBR)을 통해 물리 메모리에 있는 페이지 테이블을 찾고 페이지 번호를 인덱스로 프레임 번호를 알아낸 다음 오프셋을 이용해 물리주소로 변환을 한다.
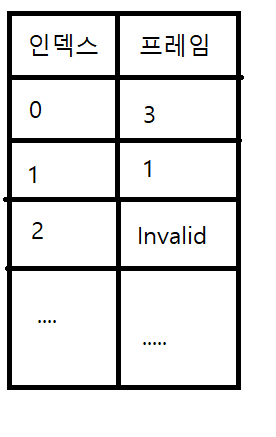
페이지 테이블에 Invalid는 스왑영역, 즉 하드디스크에 저장되어있다는 의미이다.
세그멘테이션과 마찬가지로 PTBR도 컨텍스트 스위칭이 일어날때마다 해당 프로세스의 것으로 업데이트 한다.
32Bit CPU가 어떻게 주소변환을 하는지 알아보자.
32Bit 시스템에서 가상 메모리의 크기는 2^32바이트 대략 4GB이다.
페이지의 크기를 16MB로 정하고 논리주소공간과 물리주소공간을 나누어보자.
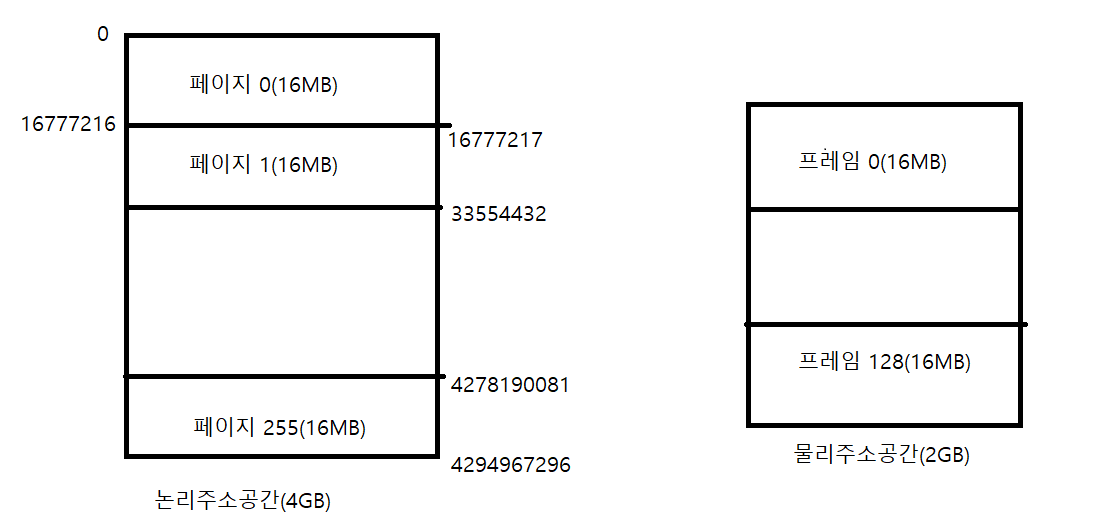
논리주소공간은 32Bit시스템에서 할당되는 가상 메모리의 크기.4GB
하나의 프로세스마다 4GB 가상 메모리가 할당된다는 것이다. (32Bit시스템에서)
-> 물론 가상 메모리의 크기는 정확히 물리 메모리 크기 + 스왑영역
-> 정확히는 나머지 2GB는 운영체제(커널)가 사용하는 영역
현재 물리주소공간(실제 메모리)은 2GB. 부족한 물리 메모리이지만 하드디스크의 스왑영역. 즉 스왑처리를 하기때문에 문제는 없다.
메모리 관리자내에 페이지 테이블은 페이지 번호가 인덱스가 된다. 해당 인덱스를 가면 프레임(물리 메모리의 단위)을 얻을 수 있다.

위 그림에서 논리주소 0x1000번지의 물리주소를 구해보자.
-> 현재 하나의 프로세스만을 가정.
페이진 넘버를 구하는 공식은
페이지 넘버 = 논리주소 / 페이지 크기
즉 1000 / 16MB(16777216) = 0이다. 즉 페이지 넘버는 0번이라는 것.
이제 오프셋을 구해보자. 오프셋의 공식은 오프셋 = 논리주소 % 페이지 크기
즉 1000 % 16777216 = 1000이다.
이제 페이지 넘버를 페이지 테이블의 인덱스로 참조한다.
0번 인덱스의 프레임번호가 3번이니 프레임 3번위치에서 아까 구한 오프셋 1000번만큼 더해주면 물리주소로 변환 된다.
또 한번 구해보자. 이번에 CPU가 물리주소로 변환하기 위해 요청한 논리주소는 0x31554432번지.
페이지 넘버 0x31554432 / 16777216 = 1. 페이지 넘버는 1
오프셋 0x31554432 % 16777216 = 14777216. 오프셋은 14777216.
페이지 넘버와 오프셋을 구했으니 페이지 넘버를 페이지 테이블의 인덱스로 참조한다.
1번 인덱스의 프레임은 1번이니 프레임 1번위치에서 14777216만큼 더해주면 물리주소로 변환이 된다.
그렇다면 스왑영역에 있는 데이터는 어떻게 처리될까.
사실 페이지 테이블에는 여러 정보가 더 존재하는데 중요하게 볼것은 유효비트.
유효비트가 0번이라면 물리메모리에 존재하는 것이고, 1번이라면 스왑영역에 존재한다.

프로세스가 페이지 2번을 요청했다고 가정해보자.
페이지 테이블의 2번 인덱스를 참조해보면 유효비트는 1이고 프레임번호는 2.
이는 스왑영역에 존재하고 프레임 2번 영역에 존재한다는 의미이다.
이제 스왑영역에 있는 데이터를 물리 메모리의 적절한 빈공간으로 옮긴다. 물리 메모리의 3번 프레임으로 옮긴다고 했을 때.
-> 만약 물리 메모리에 빈공간이 없다면 필요하지 않다고 생각되는 프레임 공간을 스왑영역으로 옮기게 된다.(스왑아웃)
-> 이 스왑아웃은 어떤게 적절한지 운영체제(커널)이 판단한다. 이 판단 기준을 페이지 교체 알고리즘을 통해 구한다.
페이지 테이블의 2번 인덱스는 유효비트가 0으로 프레임 넘버를 3으로 바꾼다.
마지막으로 프로세스에게 해당 데이터를 참조하게 된다.
대충봐도 세그멘테이션과 무언가 비슷하게 동작한다는 것을 알 수 있다.
그럼 이 둘의 차이점은 무엇일까.
바로 페이지의 크기.
세그멘테이션은 프로세스마다 크기가 달라 Bound Address를 가지지만, 페이징은 모든 페이지의 크기가 동일하기에
크기를 표현하는 Bound Address는 필요하지 않다.
페이징은 이러한 특징덕에 외부단편화는 발생하지 않지만 내부단편화가 발생한다.
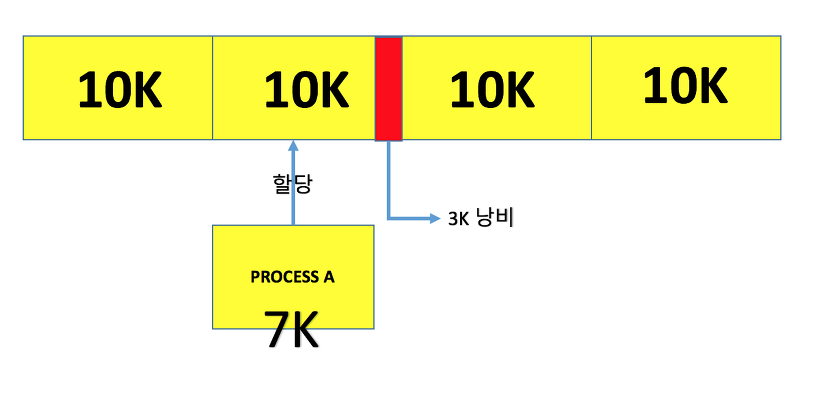
위 그림은 페이지의 크기를 10K로 잡음.
정해진 크기의 페이징보다 프로세스의 정보가 작으면 그만큼 공간이 낭비되고 이를 내부 단편화가 발생.
하지만 외부 단편화에 비하면 많은 공간이 낭비되는것이 아니기에 이를 심각하게 생각하지는 않는다고 한다.
-> 외부 단편화가 해결하기 더 힘들기에
페이지 교체 정책
프로세스는 데이터 접근을 위해 메모리를 참조한다.
해당 데이터가 메모리에 없으면 Page Fault가 발생한다.
그렇기에 해당 페이지를 스왑영역에서 메모리로 불러들여야 한다.
만약 물리 메모리에 공간이 없다면 그 프레임들 중 하나를 선택해서 스왑영역으로 옮겨야 한다.(스왑 아웃)
어떤 프레임을 선택할지 결정하는 정책을 페이지 교체 정책이라 하고 이는 여러가지 방법이 존재한다.
1. 무작위 방법(Random)
-> 이 방법은 지역성을 고려하지 않기에 성능에 좋지않아 거의 사용되지 않는다.
2. FIFO
-> 이 방법은 메모리에 올라온 프레임들 중 가장 오래된 프레임을 교체하는 방식.
-> 하지만 이 프레임이 자주 사용되는 것이라면 해당 프레임이 교체된다는 것은 공평하지 않다.
-> 실제로 자주 사용되는 프레임도 교체될 수 있다.
-> 이러한 단점이 있지만 구현이 간단하고 성능이 나쁘지는 않아 간단히 변형하여 사용한다고 한다.
3. Optimum
-> 앞으로 가장 오랫동안 쓰이지 않을 프레임을 선택하는 방법.
-> 하지만 앞으로 누가 가장 사용되지 않을지를 판별하는건 쉽지가 않다.
4. LRU(Least Recently Used)
-> 최근에 가장 사용이 적은 프레임을 선택하는 방식
-> 지역성 이론에 따르면 최근 사용한 데이터가 앞으로도 사용될 확률이 높기에 최근에 사용을 가장 적은 프레임이 앞으로도 사용될 확률이 적다는 결론이 나온다.
-> 하지만 프로그램이 지역성을 뛰지 않을땐 성능이 떨어진다.
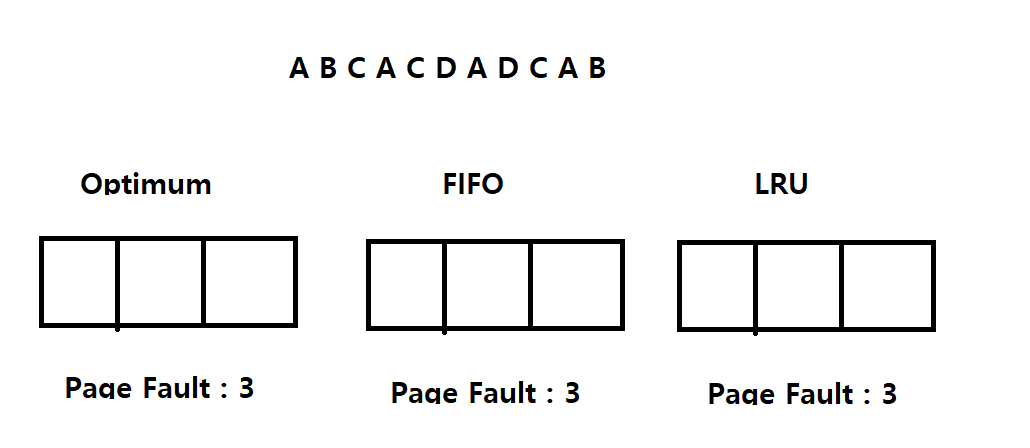
위 그림과 같이 각 페이지 교체 정책으로 나눈 메모리들이 있다고 하고.
페이지가 A,B,C,A,C,D,A,D,C,A,B 순서로 요청된다고 가정해보자.
처음에는 세개의 메모리 모두 비어있으므로 A,B,C가 각각요청될 때마다 페이지 부재(Page Fault)가 발생한다.
-> 그렇기에 Page Fault : 3
이제 메모리에 각각 A,B,C를 올리고, 그다음 A의 페이지를 처리한다고 해보자.
4. A 페이지 요청. Optimum,FIFO,LRU 모두 메모리에 A페이지가 존재하므로 Not Page Fault.
5. C 페이지 요청. Optimum,FIFO,LRU 모두 메모리에 C페이지가 존재하므로 Not Page Fault.
6. D 페이지 요청. Optimum FIFO, LRU 모두 메모리에 D페이지가 존재하지 않으므로 Page Fault.
-> Optimum은 여기서 남은 페이지의 요청들 A,D,C,A,B를 훑어보고 가장 오랫동안 사용되지 않을 페이지를(B) 스왑영역으로 옮긴 후 스왑영역에 있는 D 페이지를 메모리에 올린다.
-> FIFO는 가장 먼저 들어온 페이지인 페이지 A를 스왑영역으로 옮기고 A가 있던 자리에 D를 가져온다.
-> LRU는 최근에 가장 사용이 적은 페이지를 내보내기에 참조수를 계산한다. A는 2번, B는 1번 C는 2번. B를 가장 덜 사용되어있으므로 B를 스왑영역으로 보낸 후 B가 있던 자리에 스왑영역의 D페이지를 메모리에 올린다. (스왑인)
이런식으로 처리를 해보면 Optimum,FIFO,LRU는 각각 페이지 부재가 5,6,5가 발생하게 된다.
-> FIFO가 가장 성능이 좋지않다는 것을 알 수 있음.
-> 실제로 FIFO는 자주 사용되는 페이지도 교체되기에 성능이 떨어진다.
스레싱과 워킹셋
물리 메모리의 크기가 작고, 메모리에 여러 프로세스가 올라온다면, 필연적으로 프로세스의 일부는 스왑영역에 올라가야 하며, 스케쥴링을 통해 컨텍스트 스위칭이 되었을 때 다른 프로세스의 페이지를 요청할 때마다 스왑처리가 빈번히 일어날것이다. 즉 Page Fault가 자주 일어난다는 것. 이는 CPU의 작업 처리보다 스왑처리에 대한 작업량이 더 많이 늘어나 CPU사용률이 떨어지게 된다. 이를 스레싱이라 함.
-> 간단히 말해 Page Fault가 연속적으로 발생하여 프로세스 수행시간보다 페이지 교체 시간이 많은 상태. (스레싱)
이를 하드웨어적으로 해결하기 위해서는 물리 메모리의 크기를 늘려주면 된다. 2GB -> 4GB.
하지만 메모리의 크기를 늘린다해서 성능이 무작정 좋아지는건 아니다.
-> 스레싱이 존재하지 않는다고 가정한다면 4GB의 메모리나 16GB메모리나 성능은 같기에.
한 프로세스가 실행될 때 너무 많은 페이지를 할당하면 다른 프로세스가 사용할 페이지가 줄어들기 때문에 효율이 줄어든다. 반대로 너무 적은 페이지를 할당하면 빈번하게 Page Fault가 발생하고 스왑요청이 많아 스레싱이 발생한다.
이를 해결하기 위해 프로세스가 실행되면 일정랼의 페이지를 할당하고, Page Fault가 발생하면 더 많은 페이지를 할당한다. 반대로 Page Fault가 너무 적게 발생하면 페이지를 과하게 할당해 메모리가 낭비되는것이라 판단하고 페이지를 회수한다.
-> 이렇게하면 프로세스가 실행되는 동안 해당 프로세스에게 맞는 적절한 페이지 수가 결정된다.
적절한 페이지수를 결정했다면 어떤 페이지들을 유지할지를 결정해야 한다. -> 지역성 이론
-> 현재 메모리에 올라온 페이지는 다시 사용할 확률이 높기 때문에 하나의 세트로 묶어서 메모리에 올린다. 이를 워킹셋(working set)이라 한다.
워킹셋은 프로세스가 준비상태에서 실행상태가되는 컨텍스트 스위칭을 할 때 사용된다.
'CS > 운영체제' 카테고리의 다른 글
| [OS] 스레드 동기화와 교착 상태(Deadlock) (0) | 2022.04.06 |
|---|---|
| [OS] 스케줄링 알고리즘과 우선순위 (0) | 2022.04.04 |
| [OS] 프로세스와 쓰레드 (0) | 2022.04.03 |
| [OS] 컴퓨터 구조 개요 (0) | 2022.03.30 |
| [OS] 운영체제 개요 (0) | 2022.03.30 |



