
bdfgdfg
스트림(Stream) 본문
스트림(Stream)
스트림은 데이터 소스를 추상화하고, 데이터를 다루는데 자주 사용되는 메소드들을 정의해놓았다.
-> 스트림을 이용하면 배열 혹은 컬렉션뿐만 아닌 파일에 저장된 데이터도 모든 같은 방식으로 다룰 수 있다.
--> 즉 간결하고 가독성있는 처리가 가능.
-> 또한 가장 큰 장점은 sql 질의문처럼 데이터를 처리할 수 있는 기능도 존재한다.
스트림의 특징은 다음과 같다.
1. 스트림은 데이터(요소)를 변경하지 않는다.
2. 스트림은 Iterator와 같은 일회용. (즉 최종연산을 수행할 시 다시는 해당 스트림을 쓰지못한다. -> 재생성해야함)
3. 스트림은 작업을 내부 반복으로 처리한다
4. 스트림은 최종 연산이 수행되기전까지는 중간 연산이 수행되지 않는다.
public class Hello {
public static void main(String[] args)
{
//Function<String,Integer> fn = (String s1) -> Integer.parseInt( s1 );
List<String> list = Arrays.asList("aaa","bbb","ccc");
//기존
Iterator<String> it = list.iterator();
while(it.hasNext())
{
System.out.println(it.next());
}
// 좀 더 줄여진버전
for( String s1 : list )
{
System.out.println(s1);
}
}
}스트림을 사용한다면?
public class Hello {
public static void main(String[] args)
{
//Function<String,Integer> fn = (String s1) -> Integer.parseInt( s1 );
List<String> list = Arrays.asList("ccc","aaa","ddd");
//스트림을 이용!
list.stream().sorted().forEach(System.out::println);
}
}중간에 sorted가 붙었는데 단순 forEach로 출력은 list내부 메소드에서도 구현이 되어있기에 중간 과정을 추가했다.
또한 스트림은 중간 연산과 최종연산으로 분류할 수 있다.
public class Hello {
public static void main(String[] args)
{
//Function<String,Integer> fn = (String s1) -> Integer.parseInt( s1 );
List<Integer> list = new ArrayList();
for(int i = 0; i < 10; ++i)
list.add( (int)(Math.random() * 10) );
//스트림을 이용!
list.stream().distinct().sorted().forEach(System.out::println);
}
}여기서 중간연산은 distinct, sorted이며 최종 연산은 foreach이다.
중간 연산 : 연산 결과가 stream인 연산. 스트림에 연속해서 중간 연산을 할 수 있음.
최종 연산 : 연산 결과가 스트림이 아닌 연산. 스트림의 요소를 소모하므로 단 한번만 가능.
스트림에 정의된 중간 연산은 다음과 같다.
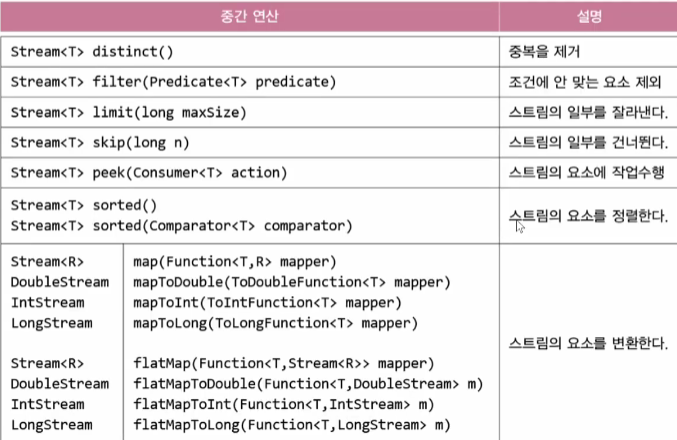
최종연산은 다음과 같다.

중간 연산은 map, flatMap, 최종연산은 reduce와 collect가 핵심이라고 한다.
스트림이 가능한 대상은 다양하다. 대표적으로 컬렉션이 있고, 배열, 임의의 수등등..
임의의 수로 랜덤한 데이터를 뽑는 스트림을 만들어보자.
public class Hello {
public static void main(String[] args)
{
//Integer와 같은 객체타입이 아닌 기본형타입의 스트림도 존재한다.
IntStream itStream = new Random().ints();
itStream.limit(5).forEach(System.out::println);
}
}-78603557
-554337742
-49515737
544370437
1267367249
범위는 Integer.MIN_VALUE <= ints() <= Integers.MAX_VALUE
위 코드를 보면 limit라는 중간연산을 했는데, 그 이유는 ints와 같은 메소드는 스트림을 크기가 정해지지 않은 무한 스트림을 반환하기에 스트림의 크기를 제한해주어야 한다.
Stream클래스의 iterate, generate도 존재하는데 해당 메소드들은 람다식을 매개변수로 받아서 이 람다식에 의해 계산되는 값들을 요소로 하는 무한 스트림을 생성한다.
-> 무한 스트림은 항상 조심. limit를 떠올리자
public class Hello {
public static void main(String[] args)
{
Stream<Integer> s = Stream.iterate(0, (Integer i1) -> i1 + 2 );
s.limit(20).forEach((Integer i) -> System.out.print( i + " " ) );
}
}0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38
iterate는 씨드값으로 지정된 값부터 시작해 람다식에 의해 계산된 결과를 반복한다.
generate도 iterate와 같이 람다식에 의해 계산되는 값을 요소로 하는 무한 스트림을 생성해서 반환하지만, iterate와 달리 이전 결과를 이용해 다음 요소를 계산하지 않는다.
두 스트림을 연결할 수도 있다.
public class Hello {
public static void main(String[] args)
{
String[] str1 = {"123","456","789"};
String[] str2 = {"ABC","abc","DEF"};
Stream<String> s1 = Stream.of(str1);
Stream<String> s2 = Stream.of(str2);
Stream<String> s3 = Stream.concat(s1, s2);
s3.forEach(System.out::println);
}
}123
456
789
ABC
abc
DEF
중간연산 좀 더 파보기
이미 해본 limit,distinct등은 넘어간다. filter와 같은 중간연산도 주어진 조건(Predicate)에 맞지 않는 요소를 걸러내는 간단한 연산.
sorted도 간단하지만 더 편리한 기능도 밑과 같은것들이 있다.

특히 Comparator의 여러 편리한 static메소드들도 존재하는데 대표적으로 comparing.
람다식으로 넘겨준 값을 기준으로 정렬기준을 잡는다.
public class Hello {
public static void main(String[] args)
{
List<Student2> list = new ArrayList();
for(int i = 0; i < 10; ++i)
{
int age = (int)(Math.random() * 10) + 10;
int privateNum = (int)(Math.random() * 20) + 1;
list.add(new Student2(age,privateNum));
}
list.stream().sorted(Comparator.comparing(Student2::getAge)
.thenComparing(Student2::getPrivateNum)
).forEach(System.out::println);
}
}age : 10 privateNum : 3
age : 10 privateNum : 6
age : 12 privateNum : 11
age : 13 privateNum : 8
age : 13 privateNum : 17
age : 15 privateNum : 19
age : 16 privateNum : 8
age : 16 privateNum : 20
age : 18 privateNum : 8
age : 19 privateNum : 6
즉 age순으로 정렬을 하되, 같은 나이라면 privateNum을 기준으로 정렬.
map ★★
스트림의 요소에 저장된 값중에서 원하는 필드만 뽑거나 특정 형태로 변환해야 할때가 있음.
이 떄 사용하는게 map, map은 함수형 인터페이스인 Function이 매개변수이므로 관련된 람다식을 넘겨줘야한다.
public class Hello {
public static void main(String[] args)
{
List<Student2> list = new ArrayList();
for(int i = 0; i < 10; ++i)
{
int age = (int)(Math.random() * 10) + 10;
int privateNum = (int)(Math.random() * 20) + 1;
list.add(new Student2(age,privateNum));
}
// 한번해봄.
list.stream().map( new Function<Student2,Integer>() {
@Override
public Integer apply(Student2 s1)
{
return s1.getAge();
}
}
).forEach(System.out::println);
System.out.println();
list.stream().map(Student2::getAge).forEach(System.out::println);
}
}12
14
11
10
17
14
16
13
15
16
12
14
11
10
17
14
16
13
15
16
map은 유용하게 잘 쓰인다.
Optional<T>와 Optionallnt
최종 연산의 결과타입이 Optional인 경우가 있다.
Optional<T>는 T타입의 객체를 감싸는 래퍼 클래스. 즉 Optional타입의 객체는 모든 타입의 참조변수를 담을 수 있다.
String str = null;
Optional<String> opt = Optional.of(str);
String str1 = opt.get(); // get은 내부요소가 null이면 exception발생
String str2 = opt.orElse(""); // 내부요소가 NULL이면 ""를 반환.스트림의 최종연산
최종연산은 스트림의 요소를 소모해 최종 결과를 얻어낸다. (이후 해당 스트림은 더이상 사용불가)
조건검사 - allMatch,anyMatch,noneMatch,findFirst,findAny
통계 - count,sum,average,max,min
위 연산들은 간단하기에 결과만 보고 넘어간다.
public class Hello {
public static void main(String[] args)
{
List<Student2> list = new ArrayList();
for(int i = 0; i < 10; ++i)
{
int age = (int)(Math.random() * 10) + 10;
int privateNum = (int)(Math.random() * 20) + 1;
list.add(new Student2(age,privateNum));
}
boolean bRet = list.stream().anyMatch( (Student2 s1) -> s1.getAge() <= 12 );
Student2 retStudent = list.stream().max( Comparator.comparingInt( (Student2 s1) -> s1.getAge()) ).orElse(new Student2(-1,-1));
}
}
Optional반환하는 메소드는 안전하게 orElse로 가져오는게 좋다. 혹은 orElseThrow.
reduce()는 스트림의 요소를 줄여나가면서 연산을 수행하고 최종결과를 반환한다.
collect()
스트림의 요소를 수집하는 최종 연산으로, reduce와 매우 유사.
-> 즉 간단히말하면 중간연산이 완료된 스트림의 모든 요소들을 원하는 자료형으로 변경하는 것.
-> 스트림의 요소를 수집하는 방법은 컬렉터(collector) 즉 인자로 컬렉터를 넘겨주어야 한다.
1. 스트림을 컬렉션과 배열로 변환 -> toList(), toSet, toMap(), toCollection(), toArray()
스트림의 모든 요소를 컬렉션에 수집하려면 Collectors클래스의 static메소드인 toList()와 같은 메소드를 이용하면 된다.
List<Integer> l1 = list.stream().map( Student2::getAge ).collect( Collectors.toList() );
// 특정컬렉션
ArrayList<Integer> al = list.stream().map( Student2::getPrivateNum ).collect( Collectors.toCollection( ArrayList::new ) );
// Map은 키&쌍이 필요.
Map<Integer, Student2> mp = list.stream().collect( Collectors.toMap( p -> p.getPrivateNum(), p -> p) );
collect에서도 통계 메소드를 넘겨서 통계 메소드를 호출하지 않더라도 값을 얻어올 수 있다.
public class Hello {
public static void main(String[] args)
{
List<Student2> list = new ArrayList();
for(int i = 0; i < 10; ++i)
{
int age = (int)(Math.random() * 10) + 10;
int privateNum = (int)(Math.random() * 10) + 20;
list.add(new Student2(age,privateNum));
}
long count = list.stream().count();
long count2 = list.stream().collect( Collectors.counting());
long totalSumAge = list.stream().mapToInt(Student2::getAge).sum();
long totalSumAge2 = list.stream().collect(Collectors.summingInt( Student2::getAge));
OptionalInt topAge = list.stream().mapToInt( Student2::getAge ).max();
Optional<Student2> topAgeStudent = list.stream().max( Comparator.comparing( Student2::getAge ));
Optional<Student2> topAgeStudent2 = list.stream().collect( Collectors.maxBy( Comparator.comparingInt(Student2::getAge)));
IntSummaryStatistics stat = list.stream().mapToInt( Student2::getAge ).summaryStatistics();
IntSummaryStatistics stat2 = list.stream().collect( Collectors.summarizingInt(Student2::getAge));
}
}
문자열 스트림의 모든 요소를 하나의 문자열로 연결해서 반환하는 joining 메소드도 존재한다.
public class Hello {
public static void main(String[] args)
{
List<Student2> list = new ArrayList();
for(int i = 0; i < 10; ++i)
{
int age = (int)(Math.random() * 10) + 10;
int privateNum = (int)(Math.random() * 10) + 20;
}
ArrayList<String> li = new ArrayList( Arrays.asList("aaa","bbb","ccc"));
String s = li.stream().collect(Collectors.joining());
String s2 = li.stream().collect(Collectors.joining(","));
System.out.println(s);
System.out.println(s2);
}
}
aaabbbccc
aaa,bbb,ccc
groupingBy, partitioningBy
이제부터 본격적으로 다른연산으로 대체가능한(max,counting등등..)경우를 제외하고 collect에서 유용한 기능의 메소드를 알아보자.
groupingBy는 스트림의 요소를 특정기준으로 그룹화하는 것을 의미하고
-> Function 함수형 인터페이스를 넘긴다.
partitioningBy는 스트림의 요소를 두가지, 지정된 조건에 일치하는 그룹과 일치하지 않는 그룹으로의 분할을 의미한다.
-> Predicate 함수형 인터페이스를 넘긴다.
그리고 groupingBy와 partitioningBy의 결과는 Map에 담겨 반환된다.
간단한 partitioningBy를 먼저 본다
import java.io.FileInputStream;
import java.util.*;
import java.util.function.Function;
import java.util.function.Predicate;
import java.util.stream.*;
import java.util.stream.Stream;
import java.time.*;
import java.time.temporal.ChronoUnit;
import java.time.temporal.TemporalAdjusters;
class Student
{
private String name;
private boolean isMale;
private int privateNum;
public Student(String name, boolean isMale, int privateNum)
{
this.name = name;
this.isMale = isMale;
this.privateNum = privateNum;
}
@Override
public String toString()
{
return String.format("{%s, %s, %d번}", name, isMale ? "남" : "여", privateNum);
}
public boolean getIsMale() { return isMale;}
public int getPrivateNum() { return privateNum;}
}
public class Hello {
public static void main(String[] args)
{
List<Student> list = Arrays.asList(
new Student("aaa", true, 0),
new Student("bbb", false, 1),
new Student("ccc", true, 2),
new Student("ddd", true, 3),
new Student("eee", false, 4),
new Student("fff", true, 5),
new Student("ggg", true, 6),
new Student("hhh", true, 7),
new Student("iii", false, 8),
new Student("jjj", true, 9)
);
//학생들의 성별을 기준으로 수를 그룹화
Map<Boolean, List<Student>> mp = list.stream().collect(Collectors.partitioningBy( new Predicate<Student>() {
@Override
public boolean test(Student s)
{
return s.getIsMale();
}
}));
// 학생들의 성별을 기준으로 수를 그룹화
Map<Boolean, Long> mp2 = list.stream().collect(Collectors.partitioningBy( Student::getIsMale, Collectors.counting() ));
// 성별을 기준으로 먼저 나누고, 그안에서 privateNum이 짝수/홀수를 나누어 그룹화.
Map<Boolean, Map<Boolean, List<Student>>> mp3 = list.stream().collect(
Collectors.partitioningBy(Student::getIsMale, Collectors.partitioningBy( s -> s.getPrivateNum() % 2 == 0))
);
}
}위처럼 partitioningBy에는 bool값을 반환하는 함수형 인터페이스 predicate를 인자로 넘겨주므로, Map의 키는 항상 boolean이다. 즉 true와 false되는 기준으로 요소드를 분할한 것.
groupingby에 의한 분류를 보자.
groupingby도 partitioningBy와 크게 다르지 않다. 다만 predicate 함수형 인터페이스를 넘겨줘야했던 partitioningBy와는 다르게 Function 인터페이스를 넘겨준다는게 차이점.
public class Hello {
public static void main(String[] args)
{
List<Student> list = Arrays.asList(
new Student("aaa", true, 0),
new Student("bbb", false, 1),
new Student("ccc", true, 2),
new Student("ddd", true, 3),
new Student("eee", false, 4),
new Student("fff", true, 5),
new Student("ggg", true, 6),
new Student("hhh", true, 7),
new Student("iii", false, 8),
new Student("jjj", true, 9)
);
Map<Integer, List<Student>> mp = list.stream().collect(Collectors.groupingBy(Student::getPrivateNum));
}
}그렇기에 Map의 key에 올 수 있는건 boolean뿐이 아닌 여러가지 자료형(참조형타입)이 올 수 있다.
스트림은 이렇게 가독성 및 간편함의 장점이 있지만, 내부연산은 일반연산보다 더 느린편에 속한다.
또한 문제는 최종연산에서 도중에 멈추는게 불가능하고 해당 스트림을 모두 소모해야 멈추기에 스트림을 사용하기전에 한번은 생각해보고 코드를 작성하는편이 좋지 않을까 싶다.
'웹프로그래밍 > Java' 카테고리의 다른 글
| 자바 소켓프로그래밍 (0) | 2023.08.01 |
|---|---|
| 자바의 직렬화 (0) | 2023.08.01 |
| 람다 (0) | 2023.07.30 |
| 쓰레드 (0) | 2023.07.29 |
| 제네릭스 & 어노테이션 (0) | 2023.07.29 |


